庚子春节,COVID-19病毒肺炎疫情由武汉首发并快速向全国蔓延,全国人民群众的生命健康受到极大的威胁,举国上下众志成城,亿万军民戮力同心,全面打响了夺取疫情防控的阻击战。我院生物数学团队在唐三一教授带领下,联合西安交通大学生物数学团队和加拿大York大学吴建宏教授团队,通过融合多源数据,分三个阶段对COVID-19病毒肺炎疫情预测预警建模和防控机制有效性进行了系统分析。
第一阶段:利用2020年1月23号前的全国累积报告病例数,基于COVID-19的传播机理和密切跟踪隔离策略,建立了传播动力学模型。通过模型辨识和参数估计,早期数据预测(1月10日至1月22日间的报告疫情数据)得到COVID-19传播早期基本再生数为6.47 (95%置信区间为 5.71-7.23),截止1月29日24时预测报告病例数为7723(实际全国报告数据为7711)。上述基于早期疫情估计得到的基本再生数远大于2003年的SARS,说明了COVID-19的传染性远大于SARS。2月7日世界卫生组织通过分析中国约1.7万例患者数据后指出:COVID-19的传染性远高于SARS,但死亡率更低(有关死亡率的模型预测见后面第三阶段的工作)。由此可见,团队通过建立比较符合实际的数学模型并结合少量的报道数据,提前2个周以上给出了早期COVID-19病毒传播力非常强的预警,并对未来一周的疫情给出的准确预测。我们也采用敏感性分析讨论了1月22日前全国防控措施的有效性以及在降低再生数中的重要作用,即疫情早期的高传播风险如何通过强有力的非药物防控措施得到减缓。团队早期研究成果“Estimation of the Transmission Risk of the 2019‐nCoV and Its Implication for Public Health Interventions”已经在杂志《Journal of Clinical Medicine》上在线发表。
第二阶段:自2020年1月23日起武汉开始实施封城策略,各地也相继采取了出行限制策略。早期的模型不能刻画自2020年1月23日凌晨后实施的不断加强的封城、密切跟踪隔离、疑似病例的检测率、筛查率等措施。团队成员依据中国特色的突发疫情防控策略,提出刻画围堵和缓疫策略的非自治函数,建立非自治的COVID-19病毒疫情传播、预测预警以及防控机制评估系统,融合多源数据实现非自治系统的模型辨识,估计了该系统的“有效再生数”。在国家严格的疫情防控措施下,计算结果显示“有效再生数”随着防控措施的加强逐渐减小,即新发感染数开始逐渐下降。在不同条件下得到每天在院病人数将在2月4日-8日左右达到峰值。
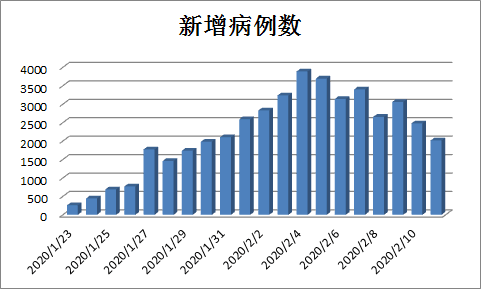
图1:近一段时间全国每日新增病例数。
评估从2月8日开始人员流动规模对疫情的影响,特别是疫情再度爆发的风险。研究结果表明:在维持1月23日以来的防控措施下,每日1-2百万的人口流动是风险较低的,但是更多的人口流动比如3百万及以上就极有可能导致二次爆发。当然非疫区的人员流动规模适当扩大,二次爆发的风险也是比较低的。该研究部分成果在《Infectious Disease Modeling》接收发表。上述风险分析部分结果已报相关决策机构。
第三阶段:根据当前全国超强的防控策略,特别是截止2月7日凌晨全国密切跟踪隔离累积人数超过34万,累积疑似病例接近6万(应该包含于累积跟踪隔离人数),且与普通发热门诊病例交叉混合。从有关专家报告中得知很大比例的确定病例来源于跟踪隔离和疑似人群,这说明我国当前COVID-19病毒疫情的最终走向取决于这两个群体的大小,以及针对这两个群体的检测率、检出比例等关键因子。由此可见,传统的SEIR(严格来说应该是SEIHR, H表示每天在院病例数, I为未发现或未确诊的感染者)模型不能有效评估我国COVID-19传播疫情。团队成员及时更新,创新性地提出了适合当前特点的COVID-19传播疫情防控模型,如下图所示:
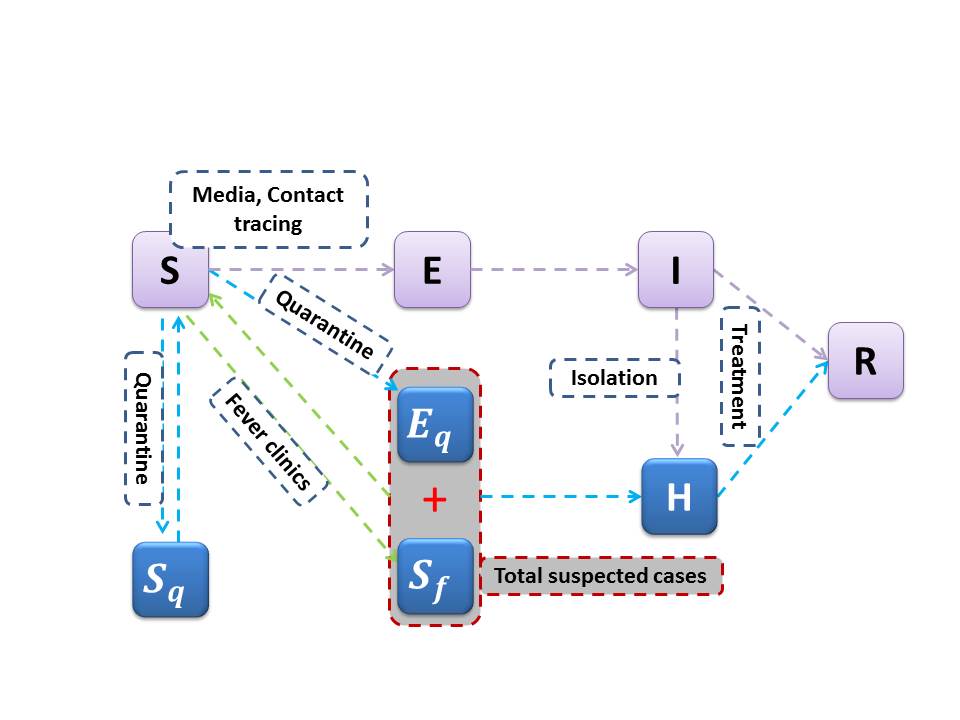
图2:具有密切跟踪隔离和疑似病例仓室的2019-nCov的传播动力学模型示意图
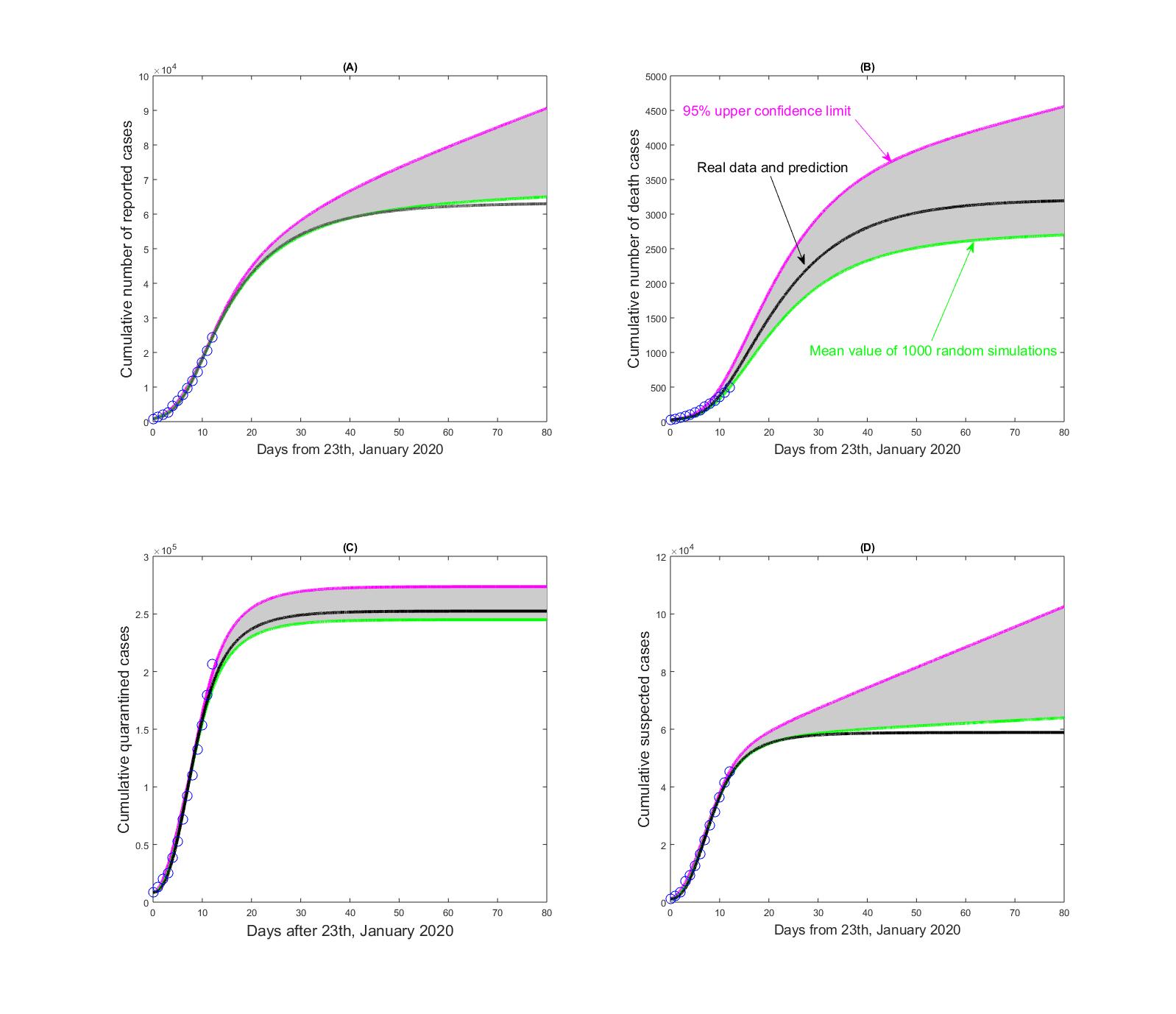
图3:累积报告病例数、累积死亡病例数、累积跟踪隔离人数(不含疑似病例)、累积疑似病例数的数据拟合和预测。圆圈为实际数据,黑色实线为模型求解及预测。绿色曲线和粉色曲线分别代表不确定分析和数据随机性(1000次随机模型与估计)后得到的均值和95%的置信上限。
通过多源数据交叉验证和模型参数估计,分析了针对跟踪隔离和疑似人群检测率、检出比例等关键因子对我国疫情动态发展的影响,得到了这两个群体人群累积规模的稳定是我国COVID-19疫情峰值到来的前提。有关累积报告病例数、累积死亡病例数、累积跟踪隔离人数(不含疑似病例)、累积疑似病例数的数据拟合和预测见图3。 敏感性和不确定分析都显示累积跟踪隔离人数、累积疑似病例数群体规模基本趋于稳定,意味着峰值即将到来,累积报告病例数增幅大幅下降。从不确定性分析可以看出,未来疫情发展中累积疑似病例和累积报告死亡病例规模不确定性相对较大,受随机性影响较强, 直到2月10日24时,累积报告死亡病例已经达到了1016例(与预测值吻合),注意到只有累积死亡病例数的预测曲线完全落在不确定性分析的95%的执行上限的偏中间的位置。
因此关注重症病例提高治愈率,谨防复工复课等返程集聚性爆发的随机发生对疫情带来的冲击应该得到高度关注。在当下国家不断加强隔离、检测和检出率的同时,如果大众持续的、严格的做好自我隔离和保护,正如我们在第二阶段预测的峰值将在在2月8日左右到来一样,我们坚信未来COVID-19疫情应该向着我们预测的黑色曲线甚至更好的方向发展。
任何一项基于数学模型的预测结果,都不应该脱离条件的制约。因此,在了解数学模型对疫情预测的各种结果时,一定要清楚地了解该预测是在什么样的条件下获得的。也正是基于这些条件,公众才能理解某些看似“可怕”的预测结果背后的真正科学意义。作为科研工作者,主要是发挥自己的专业特长,通过合理、科学的假设,建立符合中国特色的数学模型,通过研究,服务于国家突发性重大传染病的防控。
作为长期从事突发性传染病预测预警的建模与防控机制的我校唐三一教授研究团队,在疫情传播、爆发期间对疫情传播风险进行了科学评估,对疫情的复杂演化和围堵缓疫策略的有效性、时效性以及影响疫情严重程度的关键防控因子的甄别进行了系统研究,为疾病预防控制部门提供重要的决策依据。早期WHO给出了COVID-19传播的基本再生数为1.5-2.5,此后有团队给出了基本再生数为3.6-4.0,目前各方面证据显示COVID-19的传染力非常强,要远远高于2003年的SARS。然而,对于突发性传染病,一个核心问题是如何在其爆发的早期,能够基于少量的实时更新的数据,相对准确的给出其传播风险的预测和预警,这对于传染病的防控至关重要。与此同时,为了适应COVID-19疫情发展与不断加强的防控策略,数学模型也应该根据实际问题不断更新和改进,才能有效评估防控机制的有效性和时效性。因此,通过此次疫情的建模与防控机制研究,研究团队深刻地感受到:尽快建立了解中国国情的重大公共卫生事件数学预测团队和预测预警平台,以便对突发性传染病进行快速的预测预警,服务于国家公共卫生突发事件防控的重大需求已经迫在眉睫。

 当前位置:
当前位置:



